

Etiquetas para Ecommerce
Felipe
Tabla de contenidos
ToggleLas tags o etiquetas (Folcsonomías), son términos simples que hablan de una propiedad o característica de la información tratada, pero no la define ni la agrupa jerárquicamente.
Es información sobre la información o un metadato, con los metadatos podemos crear Ontologías que son esquemas conceptuales relacionados entre uno o varios dominios con la finalidad de facilitar la comunicación o el intercambio de información entre diferentes sistemas y entidades.
¿Qué son las entidades?
Una entidad es aquel elemento que puede ser perceptible por un sistema animado y tratado de forma concreta, abstracta, particular o universal.
Por ejemplo:
Entidad Barcelona -> Ciudad
Entidad Barcelona -> Equipo de fútbol
¿Qué es un nodo?
Un nodo o unidad de información puede tener una o más tags (etiquetas) formando estructuras de datos , relacionadas o no, cada uno de los cuales se refiere a una característica específica del objeto, pero que no lo categoriza y que nos puede llevar a generar teorías de grafos proporcionándonos estructuras de formas matriciales, secuenciales o de conjunto. Por ejemplo:
Objeto -> Manzana
Tags (Etiquetas) -> roja, dulce, sabrosa
En este caso, cada uno de los tags habla sobre una propiedad del objeto Manzana, pero no son categorías a la que éste pertenezca. Se trata de una estructura plana de términos que lo caracterizan, en un esquema de es o tiene.
Como generar estructuras jerárquicas mediante categorías
Las categorías (Taxonomías) son un sistema de asociación de contenido con uno o más temas. Permiten definir y agrupar la información estableciendo relaciones. Las categorías tienen estructuras planas (un nivel) o jerárquicas (múltiples niveles), estos niveles de jerarquía no es conveniente que pasen de más de tres, ya que cuanto mayor es la profundidad del sitio web más complicado es que el robot profundice y los recorra completamente. Los niveles establecidos mediante la categorización establecen una relación de dependencia del tipo pertenece a:
Por ejemplo:
* Recetas
* Postres
* Fruta
# Manzanas -> roja, dulce, sabrosa
# Peras
# Naranjas
# Sandías
Dado que ambos esquemas son diferentes, pero no son opuestos, es posible utilizarlos simultáneamente para obtener una mayor riqueza en la organización de la información.
Los tags ( Etiquetas ), permiten enriquecer al buscador pero se hace necesario la desambiguación que producen por sí mismas al no estar dentro de una estructuración jerárquica, ya que, aunque identifican los términos más relevantes de un contenido, estos por sí mismos no tienen sentido pues hemos visto cómo hablan sobre propiedades.
Las tags ( Etiquetas ) son particularmente importantes para contenido no textual, como fotografías, videos y audio, casos en los que no es fácil para el buscador contextualizar automáticamente debido a que no es capaz de realizar abstracción de conceptos.
Sin embargo una estructura de clasificación es útil, por ejemplo, para establecer un esquema de navegación jerárquico asociado a las expectativas del usuario y la findability del sitio web mejorando así la experiencia de navegación por el mismo y por tanto afectando directamente al revenue en caso de que se trate de un sitio transaccional o al engagement que se pueda producir en sitios por ejemplo informacionales.
Análisis de contenidos
Profundizando más en lo que sería el análisis del contenido, la desambiguación del mismo y la predicción futura de éste, se hace necesario cada vez más de la utilización de entidades incluidas dentro de N-Gramas o Cadenas de Markov que facilitan la consecución de eventos definiendo estados.
Así, anticipándonos a estados definidos mediante estas entidades que refuercen las hipótesis o estructuras definidas que ya están preestablecidas mediantes Corpus o Tesauros, podremos crear estructuras sintácticas que sean, además, semánticamente correctas.
Inteligencia Artificial
Sin duda, todo este tipo de análisis de contenido se puede disgregar en varias vertientes como ocurre con SyntaxNet, un analizador sintáctico de código abierto integrado con TensorFlow que aprende mediante algoritmos de machine learning como Parsey McParseface a analizar la estructura lingüística de la lengua, y que puede explicar el papel funcional de cada palabra en una frase dada pero que si queremos elevarlo a nivel mundial es complicado debido a que no existen bases de datos de conocimiento de todos los idiomas existentes en este momento.
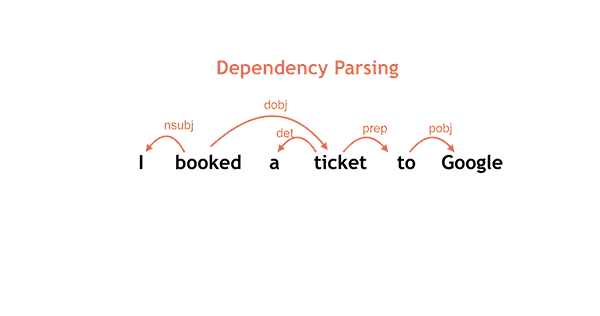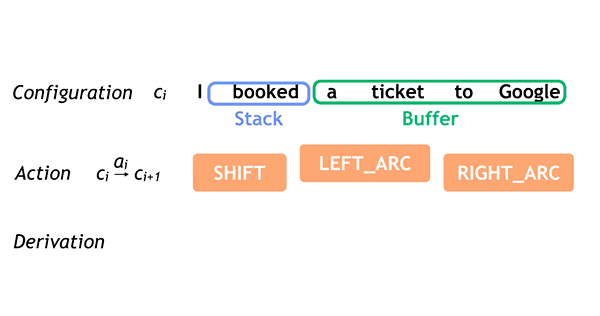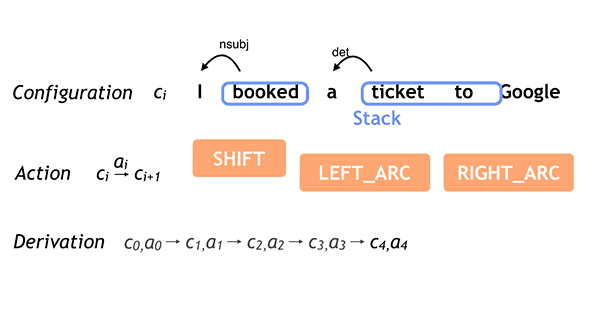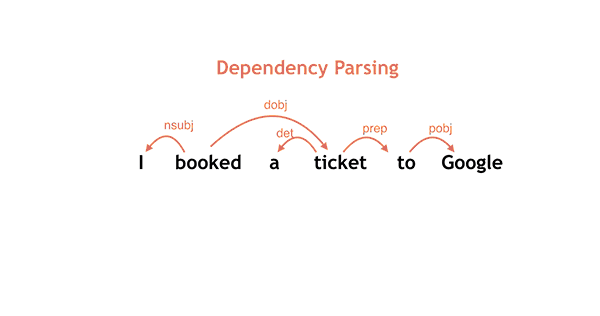
Como ciencia de la computación, el procesamiento del lenguaje natural es una de las vertientes más importantes dentro de los buscadores, así lo demuestran algunos de los recientes artículos sobre AI donde podemos ver como se tratan y corrigen algunos errores gramaticales mediante los sistemas mencionados anteriormente.
Estos sistemas enriquecen todavía más a los analizadores sintácticos pudiendo establecer mejores relaciones entre los contenidos al poder determinar y ofrecer soluciones a modelos corruptos de datos derivados de grandes volúmenes etiquetados mediante sistemas de Machine Learning.
Índices de contenidos
Teniendo en cuenta que los motores de búsqueda a su vez suelen utilizar índices invertidos como sistemas de recuperación de la información debido a que sus bases de datos no vienen preestablecidas como podría ocurrir en otros sistemas de base de datos, nos encontramos todavía con mayores argumentos para utilizar sistemas de clasificación más atómicos que proporcionen una mejor experiencia tanto para el buscador como para el usuario.
No ya solo utilizando lo que serían las estructuras planas de índices si no también estructuras tridimensionales que agrupan mediante cálculos de vértices aquellas palabras que estén más cercas unas de otras pudiendo establecer relaciones semánticas que mediante el uso de capas de redes neuronales a distintos niveles de profundidad y en diversas etapas del proceso de clasificación de los contenidos obtenidos de un sitio web se hace fundamental para la buena clasificación de estos, pues el buscador intenta ofrecer resultados razonables a la búsqueda realizada de la manera más rápida y confiable posible.
Pero así como no existe un único mejor resultado ya que no existe una única mejor respuestas para todos debido a la subjetividad implícita de las preguntas y sus respuestas, el buscador intentará devolver el resultado menos malo que encuentre.
Por eso cuanto más desambiguada sea la búsqueda y el contenido, más fácil para el buscador devolver la respuesta más acorde, pues recordemos que la abstracción del concepto que a nosotros nos puede producir una palabra no se produce en un buscador.
Como crear las folcsonomías
Pero bajando de nuevo a un nivel más operativo y enfocándonos en los conceptos básicos una vez hemos visto por encima algunas partes del todo, podemos saber cuales son las folcsonomías ( tags o etiquetas) más adecuadas y demandadas agrupando por características los productos que están bajo una categoría.
Esto es tan sencillo como realizar una búsqueda en Google y ver cuales son los términos relacionados más buscados o bien mediante el conocimiento del sector debido a la facturación realizada de productos y buscador interno del ecommerce.
Por poner un ejemplo más gráfico para que se entienda, si fuésemos una ferretería online y quisiéramos etiquetar de la forma más adecuada y alineada con la demanda nuestros productos vemos claramente de un vistazo cuales serían las folcsonomías que tendriamos que tener en cuenta para potenciar nuestra sección de ventiladores en la siguiente imagen:
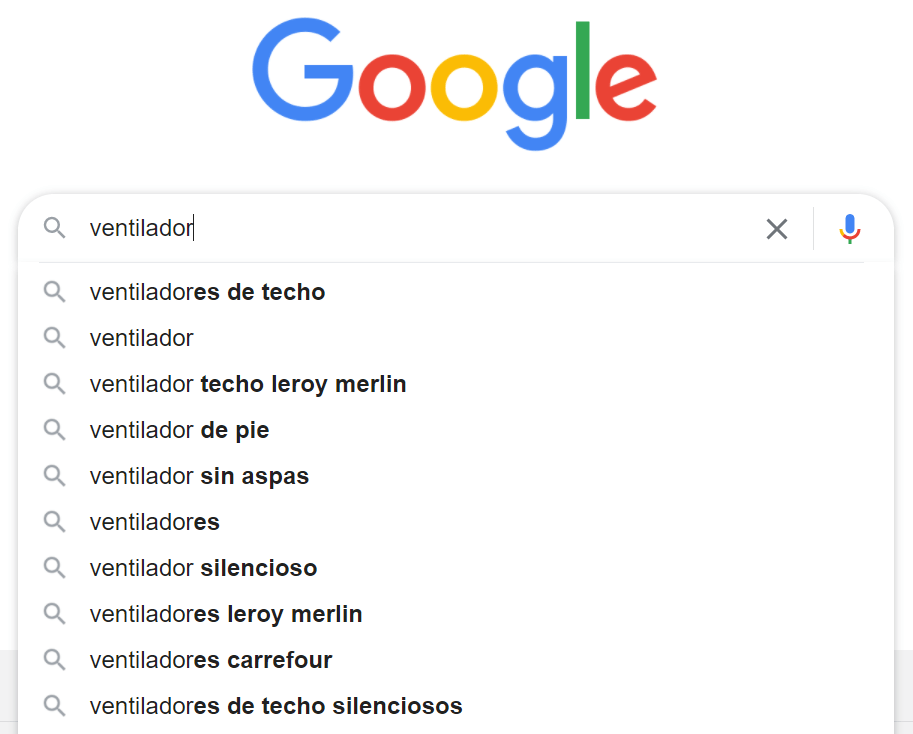
Pudiendo quedar una estructura alineada con nuestros objetivos y a la vez más enriquecida de la siguiente manera:
* Climatización ( Categoría)
# Ventiladores (Subcategoría ) -> de techo, de pie, silencioso, sin aspas ( Etiquetas )
Este etiquetado selecto proporciona un método donde se satisface de forma directa la necesidad del cliente de un producto en concreto y al mismo tiempo como hemos visto por encima con algunos conceptos básicos de clasificación semántica al buscador.
Tabla de contenidos
Toggle